
Announcing public binaries for Spack

Spack was designed as a from-source package manager, but today users can stop waiting for builds. Spack has been able to create binary build caches for several years, but the onus of building the binaries has been on users: application teams, deployment teams at HPC facilities, etc.
Today, enabled by some of the changes in Spack v0.18, and helped by the folks at AWS, Kitware, and the E4S Project we’re starting down the path towards building binaries for everything in Spack. Right now, we’ve got binaries for the following OS’s/architectures:
| OS | Target |
|---|---|
amzn2 (Amazon Linux 2) |
graviton2 |
amzn2 |
aarch64 |
amzn2 |
x86_64_v4 |
ubuntu18.04 |
x86_64 |
You can also browse the contents of these caches at cache.spack.io.
If you already know what you’re doing, here’s what you need to try out the 0.18 binary
release:
spack mirror add binary_mirror https://binaries.spack.io/releases/v0.18
spack buildcache keys --install --trust
If you aren’t familiar with Spack binaries, we’ve got instructions for using these
binaries on graviton2 nodes below. Note that you do not need to have the Spack
v0.18 release checked out; you can use this cache from the latest develop branch,
too.
What’s different about Spack binaries?
Binary packaging isn’t new, and .rpm and .deb-based distributions have been around
for years, and conda is very popular in the Python world. In those distributions,
there is typically a 1:1 relationship between binary package specs and binaries, and
there’s a single, portable stack that’s maintained over time.
Traditionally, HPC users have avoided these types of systems, as they’re not built for
the specific machine we want to run on, and it’s hard to generarte binaries for all
the different types of machines we want to support. GPUs and specific microarchitectures
(e.g., skylake, cascadelake, etc.) complicate matters further.

Spack binaries are more like those used by Nix or Guix – they are caches of builds, not specially prepared binaries, and installing a package from binary results in essentially the same type of installation as building it from source. For determinism, Packages are deployed with the dependencies they built with. One difference with Spack is that we store considerably more metadata with our builds – the compiler, microarchitecture target (using archspec), flags, build options, and other metadata. We can use a single package to build all these targets, and we can generate many optimized binaries from a single package description. Here’s what that looks like:
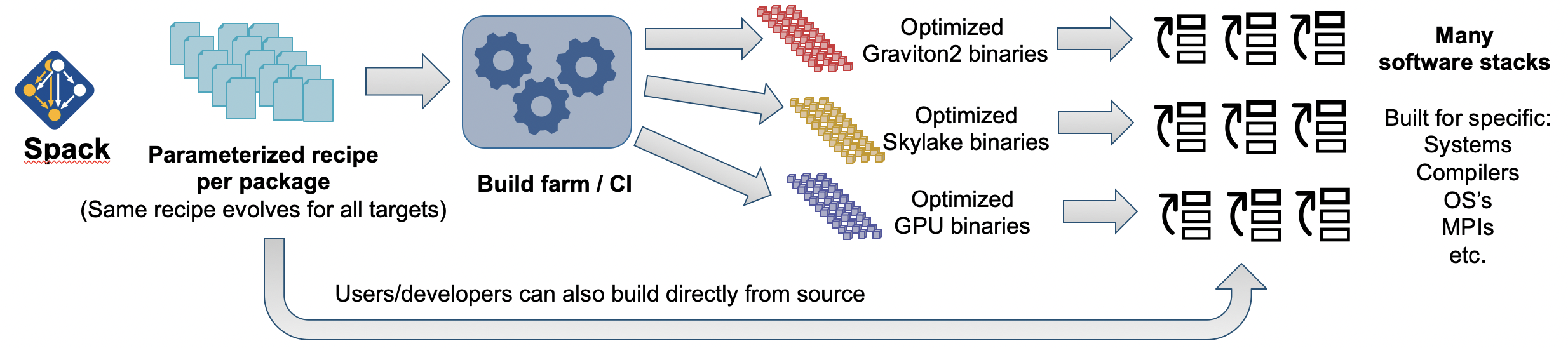
With Spack, we’re trying to leverage our portable package DSL not only for portable builds, but for optimized binaries as well. We can generate many optimized binaries from the same package files and targets, and we can maintain many portable software stacks using the same package descriptions. This reduces the burden on maintainers, as we do not need to support many thousands of recipes – only as many recipes as we have packages. And it is easy to assemble new software stacks on the fly using Spack environments. Spack binaries are also relocatable so you can easily install them in your home directory on your favorite HPC machine, without asking an admin for help.
CI for Rolling releases

To support combinatorial binaries, we are trying to push as much work upstream as possible. We don’t want to have to spend a week preparing a new release, so we’ve built cloud automation around these builds. For every PR to Spack, we rebuild the stacks we support, and we allow contributors to iterate on their binary builds in the PR. We test the builds on different architectures and different sites, and if all builds changed or introduced by the PR pass, we mark the PR ready for merge. This allows us to rely on the largest possible group of package maintainers to ensure that our builds keep working all the time.
One issue with this approach is that we can’t trust builds done in pull requests. We need to know if the PR builds work, but we may not know all contributors, and we cannot trust things built before our core maintainers approve PRs. We’ve solved this by bifurcating the build.
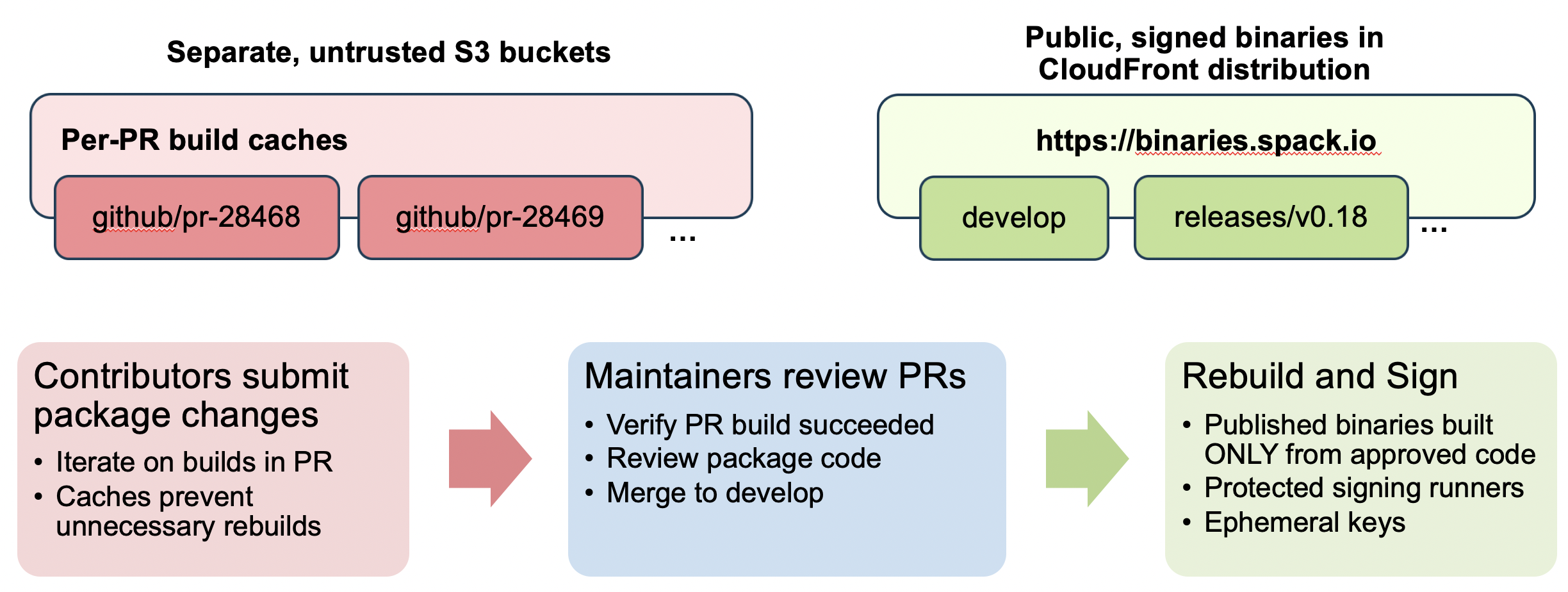
Every PR gets its own binary cache, and contributors can iterate on builds before any maintianer has a chance to look at their work (though we do obviously have to approve CI for first-time contributors). Contributors can work in parallel on their own stacks, and per-PR build caches enable them to work quickly, rebuilding only chnanged packages.
Once a maintainer looks at the PR and approves, we rebuild any new binaries introduced
in a more trusted environment. This environment does not reuse any binary data from
the PR environment, which makes us sure that bad things from an earlier PR commit won’t
slip in through binaries. We do rebuilds for develop and release branches, and we
sign in a separate environment from the build so that signing keys are never exposed to
build system code. Finished, signed rebuilds are placed in a rolling develop binary
cache or in a per-release binary cache. You can find the public keys for the release at
spack.github.io/keys
Expanding the cache
This is only the tip of the iceberg. We are currently running 40,000 builds per week in Amazon AWS to maintain our binaries, with help from the E4S project to keep them working. Kitware is ensuring that our cloud build infrastructure can scale. You can see stats from the build farm at stats.e4s.io.
We will be expanding to thousands more in the near future. Our goal is to eventually cover all Spack packages, and to make source builds unnecessary for most users and eliminate the long wait times between deciding on a simulation to run and your ability to start a scientific simulation. Expect more compilers, more optimized builds, and more pacakges.
Spack aims to lower the burden of maintaining a binary distribution and make it easy to mix source builds with binaries. Packages available in the binary mirror will install from binaries, and Spack will seamlessly transition to source builds for any packages that are not available. Users will see approximately 20X installation speedups for binary packages, and performance improvements for binary packaging are in the works.
Running Spack binaries in the cloud
On a brand new amazon-linux image, you can have optimized HPC applications installed
in only 7 commands. (If you already run Spack, it’s only 3 additional commands). You can
do this on a ParallelCluster instance if
you want to run these codes in parallel.
Let’s say you want to install gromacs.
First we need to get Spack installed. Spack has a couple low-level dependencies it needs
to be able to do anything, including a C/C++ compiler. Those aren’t on your image by
default, so you will need to install them with yum. sudo yum install -y git gcc
gcc-c++ gcc-gfortran
Now you can clone Spack from github and check out the latest release. Spack will
bootstrap the rest of what it needs to install the binary packages. You’ll also want to
setup the Spack shell integration so Spack is in your path and all its features are
available git clone https://github.com/spack/spack.git cd spack git checkout v0.18.0
. share/spack/setup-env.sh
Now you can configure Spack to use the pre-built binary caches. You can either point it
to develop or releases/v0.18.0
spack mirror add binary_mirror https://binaries.spack.io/develop
spack buildcache keys --install --trust
You can compare the public key that Spack downloads against the ones available at https://spack.github.io/keys/ for an alternate source of truth to validate source of the binaries.
Now you can download optimized HPC application binaries
spack install gromacs
Spack will install from binaries for any package spec that is available, and will aggressively reuse binaries for dependencies. You can see what’s available with Spack
spack buildcache list --allarch
Anything that’s not available will still reuse the available packages for dependencies, and will seamlessly fail over to building from source for any components for which binaries are not available.
10 minutes in and your application is already available, now you can go on to do the science you set out to do.